[DBチューニングコンテスト とんがりナレッジ] インデックス付きビューを使用してみた
2015/11/27に行われた、第2回社内DBチューニングコンテストに参加しました。
記録は残念ながら2位タイでしたが、今回もその時に実施した内容を書いていきたいと思います。
今回は、DBがSQL Serverで、競争条件は前回と同じでした。
【競争条件】 <測定ツール> - HammerDBを使用 <決勝> - TPC-H 4セッション(Scale Factor=10 )
以下は、今回使用した環境です。
【OS+DB】 OS : Microsoft Windows Server 2012 R2 DB : Microsoft SQL Server 2016 (CTP2.4) - 13.0.600.65 (X64) ※H/Wは、前回のコンテスト時に使用したものを使用しています。
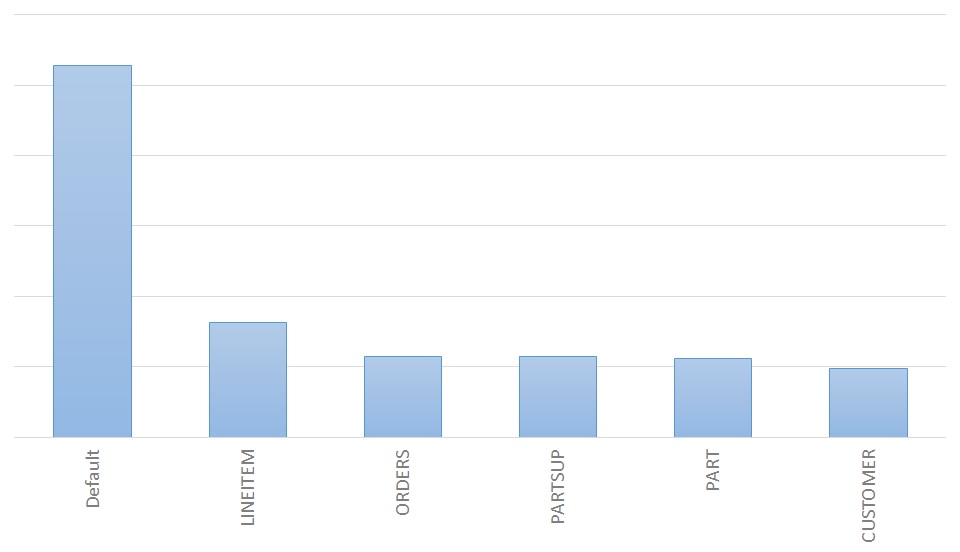
まず、最初に実施したのは、列ストアインデックスの使用です。
よりサイズが大きいテーブルのほうが、効果が大きいはずということで、対象テーブルのサイズを確認しました。
【テーブルのサイズ】 テーブル名 サイズ(MB) --------- ---------- LINEITEM 11439 ORDERS 2621 PARTSUPP 1964 PART 380 CUSTOMER 262 SUPPLIER 15 NATION 0.008 REGION 0.008
ひとまず、CUSTOMERまで、列ストアインデックスを作成してみました。
結果は、以下の通りでした。
※ベンチマークの数字は公表できないため、隠させて頂いております。
処理時間として、5倍、高速化に成功しました!!
ただ、一点疑問が残りました。
大きい順から実施したのにもかかわらず、PARTSUP,PARTでは、ほぼ効果がありませんでした。
しかし、なぜかCUSTOMERでは少し速くなりました。
理由を考えるため、クエリごとの処理時間の割合を確認してみることにしました。
<CUSTOMERへの列ストアインデックス作成前の状態>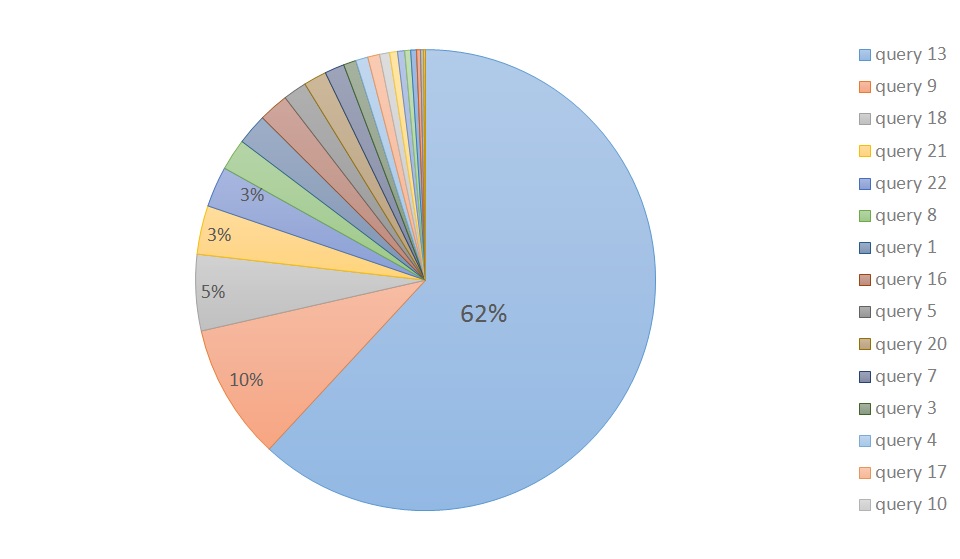
この状態では、Query13のみの実行に全体の60%以上がかかっていました。
ということで、実際のQuery13のSQLを確認してみました。
select c_count , count(*) as custdist from ( select c_custkey , count(o_orderkey) as c_count from customer left outer join orders on c_custkey = o_custkey and o_comment not like '%:1%:2%' group by c_custkey ) c_orders group by c_count order by custdist desc, c_count desc option (maxdop $maxdop)
実はQuery13は、ORDERSとCUSTOMERのみを使用しているSQLでした。
結論としては単純にサイズの問題というより、CUSTOMERをカラムナーで処理を行うほう高速になるSQLがQuery13に残っていただけという理由のようでした。
実は結構ここまでで高速化できていたので、列型で格納できるDBのすごさに、個人的に非常に驚いていました。
※行型で格納して、列型に変換して処理を行うようなDBでは、ディスクからデータを持ってくる際に
変換処理時間が必要になるためその分処理が余分に必要になり、そこのボトルネックで大分苦労したからです。
では、残りのチューニングを実施していきます。
再度、Queryごとの実行割合を確認してみました。
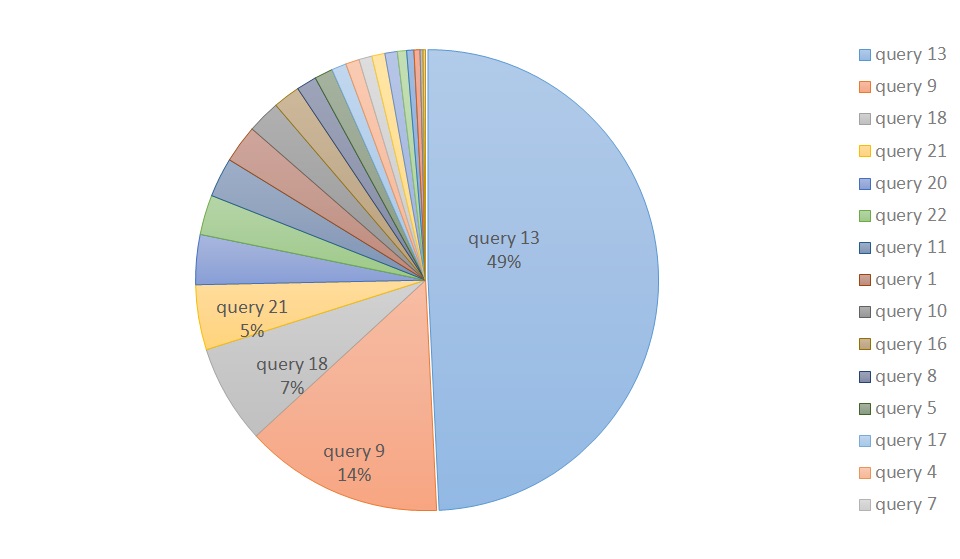
まだQuery13が半分を占めていました。。。
ここで、インデックス付きビューに手を出し始めました。
使ってみた感想は、結構、制約が厳しい!でした。
以下は、今回主に関係のあった、インデックス付きビューを使用する際の制約です。
<禁止事項> - サブクエリ - 外部結合 - 自己結合 - HAVING句 - ビューに作成する最初のインデックスは一意である必要がある
とりあえず、組み替えて速くできそうな部分だけインデックス付きビューを使用できるようにしてみました。
■Query13 select c_count , count(*) as custdist from ( select c_custkey , count(o_orderkey) as c_count from customer left outer join orders on c_custkey = o_custkey and o_comment not like '%:1%:2%' group by c_custkey ) c_orders group by c_count order by custdist desc, c_count desc option (maxdop $maxdop) ■作成ビュー CREATE VIEW [dbo].[SQL13_pending_deposits] WITH SCHEMABINDING SELECT o_custkey , count_big(*) as col_cnt FROM [dbo].[orders] WHERE ( NOT o_comment like '%pending%deposits%' ) GROUP BY o_custkey;
きちんとSQLServerのオプティマイザが自分の意図を解釈してくれるか不安だったのですが、
無事に想いが伝わった結果が以下です。
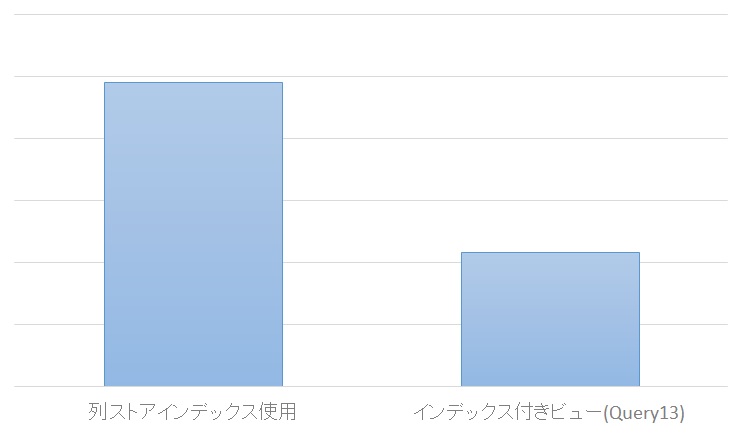
実行時間の半分をしめていたQuery13がなくなったため、実行時間も半分になりました!
ここで、再度残りのクエリーの割合を確認
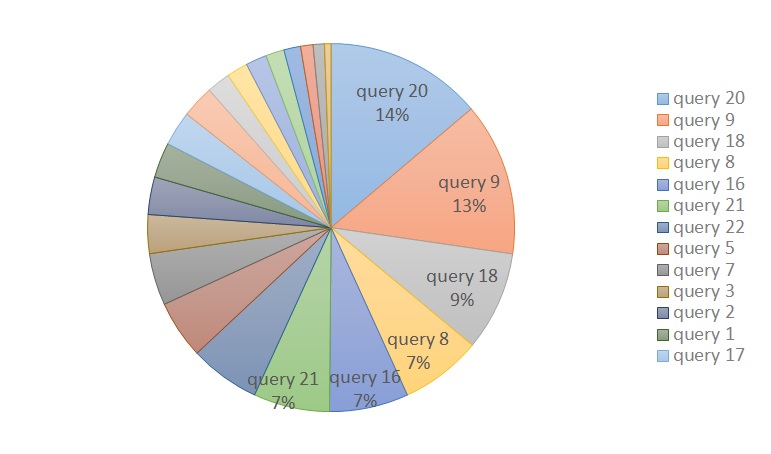
残りの、TOP3のQueryは、Query 20, Query 9 ,Query 18でした。
ひとまず、手を出しやすそうなところからということで、Query18を実施しました。
■Query18
select top 100 c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice, sum(l_quantity)
from customer, orders, lineitem
where o_orderkey in ( select
l_orderkey
from lineitem
group by l_orderkey
having sum(l_quantity) > :1
)
and c_custkey = o_custkey
and o_orderkey = l_orderkey
group by c_name, c_custkey, o_orderkey, o_orderdate, o_totalprice
order by o_totalprice desc, o_orderdate option (maxdop $maxdop)
■作成ビュー
CREATE VIEW [dbo].[SQL18] WITH SCHEMABINDING
AS select l_orderkey,sum(l_quantity) as sum_l_quantity,count_big(*) cnt
from dbo.lineitem group by l_orderkey ;
これは、havingが使えないため、havingで使用する計算結果までをインデックス付きビューで使用できるようにしました。
その結果は、以下です。
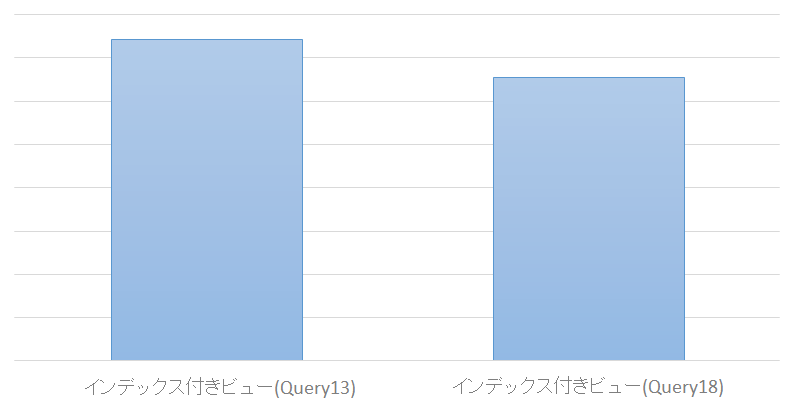
15%程度ほど速くなりました。
では、そのままQuery9も実施してみます。
■Query9 select nation, o_year, sum(amount) as sum_profit from ( select n_name as nation, datepart(yy,o_orderdate) as o_year, l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity as amount from part, supplier, lineitem, partsupp, orders, nation where s_suppkey = l_suppkey and ps_suppkey = l_suppkey and ps_partkey = l_partkey and p_partkey = l_partkey and o_orderkey = l_orderkey and s_nationkey = n_nationkey and p_name like '%:1%' ) profit group by nation, o_year order by nation, o_year desc option (maxdop $maxdop) ■作成ビュー CREATE VIEW [dbo].[SQL9_coral] WITH SCHEMABINDING AS select o_orderkey,n_name as nation, datepart(yy,o_orderdate) as o_year , l_extendedprice * (1 - l_discount) - ps_supplycost * l_quantity as amount from dbo.part, dbo.supplier, dbo.lineitem, dbo.partsupp, dbo.orders, dbo.nation where s_suppkey = l_suppkey and ps_suppkey = l_suppkey and ps_partkey = l_partkey and p_partkey = l_partkey and o_orderkey = l_orderkey and s_nationkey = n_nationkey and p_name like '%coral%';
Query9は簡単にできるかと思ったのですが、ビューが一意になっていなかったため、o_orderkeyを足して対応しました。
そして、実行結果が以下です。
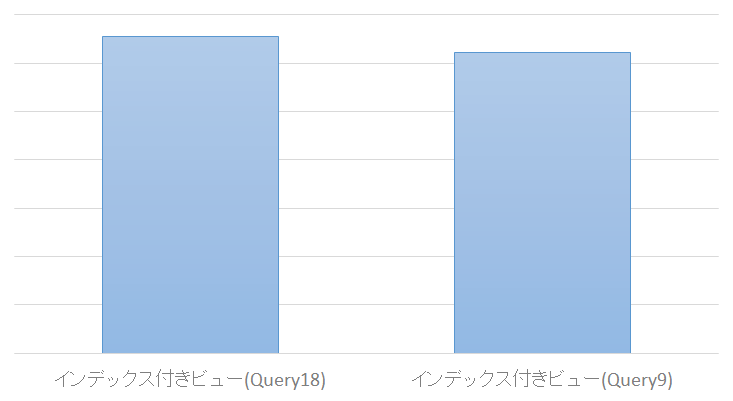
なぜか、思ったほど速くならない。。。
原因を確認するため、実際に単体でSQLを実行するときちんとリライトしていました。
しばらく悩みながら、DOPを変えるとどうなるのか試したところ、
DOPが高いとリライトしない状態になっていました!
オプティマイザがそう判断するということは、本当にインデックス付きビューを使用するより、
DOP高いほうが速いのかと確認したところ。。。
DOP 8 での実行時間 : 2 DOP 2 での実行時間 : 6 インデックス付きビューでの実行時間 : 1 ※実行時間は、時間ではなく、インデックス付きビューの実行時間を1としたときの数字です。
やっぱり、嘘でした。。。
たしかに、DOP8のほうがDOP2より速くなっていますが、インデックス付きビューを使用するよりは遅かったです。
しかも、実行時のOSのリソース状態はCPUネックの状態です。
DOP8では、8コアを全て使用しての数字のため、4session * DOP2で実行するのと実際にはあまり大差がありません。
ということで、気を取り直してDOP2で再度実行してみました。
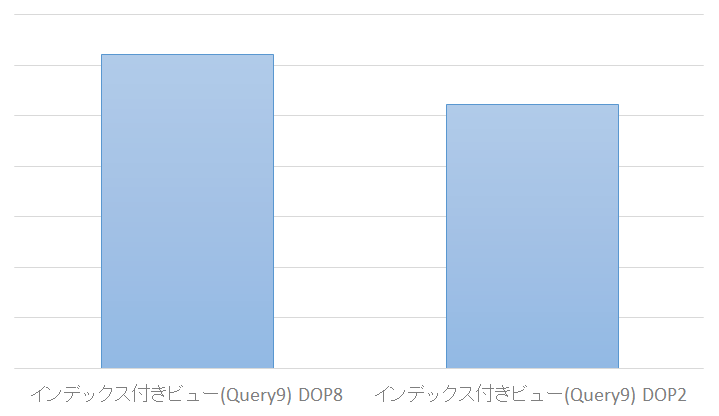
無事にリライトして、19%程度高速化できました。
で、ここで元々目標としていた数字を達成できたため、終了し、勝負に挑みました!
結果は冒頭の通り、、、
あきらかに目標値の設定をミスりました。。。
■反省点
自分の甘えを深く反省し、次回の勝負に挑みたいと思います。
また、合わせて、
自分の中の仮説
AMD FX-9590
→Core i7 4790K
にすることで、
TPCH : 約1.3倍 , TPC-C : 約1.7倍
が実現するか検証してみたいと思います。